Structured logging of PySpark applications with Log4j 2
October 03, 2021, most recent update: December 19, 2021Update 1: Vulnerability CVE-2021-44228, also known as Log4Shell, was disclosed on December 9, 2021. The original Log4j 2 version number used in this blogpost, 2.14.1, is susceptible to this vulnerability. This post has been updated to use version 2.15.0 which patches the vulnerability.
Update 2: On December 14, 2021, it was announced that the patch introduced in 2.15.0 did not adequately fix CVE-2021-44228. The newly found vulnerability has been labeled CVE-2021-45046 and has been fixed in 2.16.0. This version is now used in this post.
Update 3: Yet another vulnerability has been disclosed, CVE-2021-45105, on December 18, 2021. This vulnerability is patched in version 2.17.0 and has been updated in this post.
Centralised log management is an essential component of a modern environment. It provides the tools that are necessary to efficiently process and query the enormous amount of logs that are produced by the plethora of services that compose present-day systems. Moreover, many of those logs are likely to be ephemeral when they are produced by services deployed by on container orchestrator such as Kubernetes. In a highly automated production environment, containers are created and destroyed frequently, and troubleshooting becomes painful when their logs are not collected and stored centrally.
Parsers, filters, mutators…
Unfortunately, centralised logging is far from a plug and play solution. There is an abundance of log formats in use, and the log message contains application-specific information that tends to be even less structured. To extract the most value out of logs, they need to be properly processed to make them interpretable by the log manager. The log collector will require configuration to forward logs correctly, such as grouping multiple lines that belong together (e.g. stack traces). Configuring the pattern of the log is done by virtue of Grok filters, either on the log collector or the log manager, depending on the platform. These tasks are examples of the additional layers of maintenance that are introduced with centralised logging. Every time a new service joins the system, the logging solution needs to be reconfigured to deal with its logs. It is a tedious and boring task that is often ignored or forgotten, degrading the quality of the logging system, which in turn can lead to subpar monitoring and increased time to problem resolution.
Structured logging
To relieve engineers from this maintenance, applications can be configured to use a structured log format. Formats such as the Common Log Format or Glog are considered unstructured, because they are printed according to a fixed pattern but without identifiers. The advantage is that unstructured logs are easier to read for humans and tend to be smaller in size due to the omission of information that the reader is assumed to be familiar with. However, they require parsing to be interpretable by machines. In contrast, formats such as JSON or XML are structured; every value must be accompanied by a key. Those keys make logs readable by machines such as the log manager without additional parsing instructions. Some logs will be interpreted correctly by the log manager without any further configuration; others might require minimal work, such as mapping the key indicating the log severity, or enriching the log with a field based on other log content or machine state.
The log melting pot that is PySpark
When running PySpark applications with spark-submit, the produced logs will primarily contain Spark-related output, logged by the JVM. However, as the application is written Python, you can expect to see Python logs such as third-party library logs, exceptions, and of course user-defined logs. Effectively, this requires a complex log parsing configuration to process logs and exceptions for both the JVM and Python.
To produce structured and unified logs with PySpark applications, these two changes are made:
- Setting the log format of Spark to JSON.
- Proxying Python logs to the JVM logger.
Step one: setting Spark’s format to JSON
Even though Log4j 1 has been declared EOL for years and contains unfixed security vulnerabilities, Spark still has not migrated to Log4j 2. While it is possible to configure Spark to log in JSON format using Log4j 1, it is easier to achieve using Log4j 2. Let’s get rid of the old and embrace the new!
Replacing Log4j 1 with Log4j 2
Migrating to Log4j 2 requires some changes to the jars on Spark’s classpath, as well as an updated Log4j configuration. My team at the City of Amsterdam uses the Kubernetes Operator for Apache Spark, which uses a custom Spark image to spin up Spark applications. We cut a custom Docker image which simply replaces the old jars with the new; your approach will likely be different based on how you run Spark. I have not tested any other method.
First, remove the following Log4j 1 jars, which are located in $SPARK_HOME/jars:
- log4j-1.2.17.jar
- slf4j-log4j12-1.7.30.jar, which contains the SLF4J bindings for Log4j 1, as Spark does not call Log4j directly
Next, add the following jars to $SPARK_HOME/jars (you might have to adjust permissions):
- log4j-core-2.17.0.jar
- log4j-api-2.17.0.jar, as Log4j 2 separates the API from the core product
- log4j-layout-template-json-2.17.0.jar, to use the JSON log template
- log4j-1.2-api-2.17.0.jar, which adds an API bridge from Log4j 1 to 2, as the package structure changes in version 2
- log4j-slf4j-impl-2.17.0.jar, which provides updated SLF4J bindings for Log4j 2
Updating the configuration of Log4j
There are many methods of configuring Log4j, of which I prefer the Properties file. Support for Properties files was dropped with Log4j 2, but fortunately reinstated later; however, the syntax has changed, so a rewrite of the old Properties file is necessary.
Add a file named log4j2.properties to $SPARK_HOME/conf. The code in Listing 1.1 is added to configure an appender that logs to stderr; any output to stdout and stderr is appended to Docker container logs. The last two lines set the format to JSON.
# Set everything to be logged to the console
appenders = console
appender.console.type = Console
appender.console.name = stderr
appender.console.target = System.err
appender.console.json.type = JsonTemplateLayout
appender.console.json.eventTemplateUri = classpath:LogstashJsonEventLayoutV1.json
This appender can now be assigned to whichever logger you want to configure; however, as we want all logs to be formatted in JSON, we can just configure the root logger to use this appender. Use the appender’s name (in this case stderr) as the ref. At the same time, set the level to INFO, as we will be proxying Python logs to the JVM, and we want to prevent any INFO level logs from being swallowed in by Log4j:
rootLogger.level = INFO
rootLogger.appenderRef.stdout.ref = stderr
Under normal circumstances, we are not interested in INFO level Spark logs, so let’s configure it to a higher level:
logger.spark.name = org.apache.spark
logger.spark.level = WARN
logger.spark.additivity = false
logger.spark.appenderRef.stdout.ref = stderr
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
logger.spark.repl.Main.level = WARN
logger.spark.repl.SparkIMain$exprTyper.level = INFO
logger.spark.repl.SparkILoop$SparkILoopInterpreter.level = INFO
If you wish to configure any specific loggers, add them to this file. Listing 1.4 contains the final log4j2.properties file.
# Set everything to be logged to the console
appenders = console
appender.console.type = Console
appender.console.name = stderr
appender.console.target = System.err
appender.console.json.type = JsonTemplateLayout
appender.console.json.eventTemplateUri = classpath:LogstashJsonEventLayoutV1.json
rootLogger.level = INFO
rootLogger.appenderRef.stdout.ref = stderr
logger.spark.name = org.apache.spark
logger.spark.level = WARN
logger.spark.additivity = false
logger.spark.appenderRef.stdout.ref = stderr
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
logger.spark.repl.Main.level = WARN
logger.spark.repl.SparkIMain$exprTyper.level = INFO
logger.spark.repl.SparkILoop$SparkILoopInterpreter.level = INFO
# Settings to quiet third party logs that are too verbose
logger.jetty.name = org.sparkproject.jetty
logger.jetty.level = WARN
logger.jetty.util.component.AbstractLifeCycle.level = ERROR
logger.parquet.name = org.apache.parquet
logger.parquet.level = ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = WARN
logger.hadoop.hive.metastore.RetryingHMSHandler.level = FATAL
logger.hadoop.hive.ql.exec.FunctionRegistry.level = ERROR
Listing 1.4. The complete log4j2.properties file with JSON logging configured.
With these steps completed, Spark is now configured to log in JSON!
Step two: proxy Python logs to the JVM
To forward all Python output to the JVM, both expected and unexpected output needs to be captured. In other words, we configure a log handler which forwards logs to the JVM logger, and set an excepthook to define additional behaviour for when an exception is raised.
Configuring a proxy log handler
The JVM logger is accessible through the _jvm attribute of the SparkSession object, by referencing the fully-qualified name of the logger class. In the case of Log4j 2, this is the LogManager:
log_manager = spark_session._jvm.org.apache.logging.log4j.LogManager
For any log statements that you define yourself, you could simply get a logger instance with log_manager.getLogger() and write logs to the JVM logger directly. However, your third-party libraries will still log using Python’s logging module. By setting a custom handler as the root handler of the native logger, all logs can be rerouted to the JVM.
A class inheriting the Handler class must implement emit(self, record), which is called for every log produced. In this method, we can grab the message and forward it to the JVM logger. The implementation in Listing 2.1 is an adapted version of this helpful Stack Overflow answer.
import logging
from logging import Handler, LogRecord
from pyspark.sql import SparkSession
class SparkLog4j2ProxyHandler(Handler):
"""Handler to forward messages to log4j2."""
def __init__(self, spark_session: SparkSession):
"""Initialise handler with a log4j logger."""
Handler.__init__(self)
# ignore annotation because mypy does not like accessing private attributes
self.log_manager = spark_session._jvm.org.apache.logging.log4j.LogManager # type: ignore
def emit(self, record: LogRecord):
"""Emit a log message."""
logger = self.log_manager.getLogger(record.name)
if record.levelno >= logging.CRITICAL:
# Fatal and critical seem about the same.
logger.fatal(record.getMessage())
elif record.levelno >= logging.ERROR:
logger.error(record.getMessage())
elif record.levelno >= logging.WARNING:
logger.warn(record.getMessage())
elif record.levelno >= logging.INFO:
logger.info(record.getMessage())
elif record.levelno >= logging.DEBUG:
logger.debug(record.getMessage())
else:
pass
def close(self):
"""Close the logger."""
Next, Python’s logging module needs to be configured to only use this handler. After initialising Spark, create an instance of the custom handler. The logging module root handlers can be accessed through logging.root. Listing 2.2 demonstrates how to do so.
handler = SparkLog4j2ProxyHandler(spark_session)
for h in logging.root.handlers[:]:
logging.root.removeHandler(h)
logging.root.addHandler(handler)
This completes the configuration of Python’s logger. Any logs produced with its logging module will now be proxied to the JVM logger, which in turn produces the logs in JSON format.
Routing exceptions to the logger
The last behaviour that needs to be handled is when a Python exception is thrown. Because this output is not log related, none of the formatting is applied. Monitoring for exceptions can be a valuable addition, and adding a hook to throw exceptions through the logger makes the exception parseable and correctly formatted straight away.
The function sys.excepthook can be set to a hook method with the type signature (type, value , traceback). Listing 2.3 shows a hook method that uses the traceback module to print the exception to a string stream. logging.exception is an extension of the ERROR log level which includes exception information. This log method is used to then log the exception.
def exception_logging(exctype, value, tb):
# First print the formatted traceback to a string buffer so it can be used as the log message
output = io.StringIO()
traceback.print_exception(exctype, value, tb, file=output)
logging.exception(output.getvalue())
output.close()
The hook can be set with one line of code:
sys.excepthook = exception_logging
With this step complete, your PySpark application is fully configured to log through the JVM logger, all in JSON! I’ve wrapped the log configuration in a bootstrapping method which is published in an organisation-specific package, which makes it very easy for our data scientists to write their scripts with proper logging without having to do any of the wiring themselves.
Examples
The redacted logs shown in Listing 3.1 show several kinds of logs: a JVM log line, followed by an INFO-level log containing information from the PySpark script, and then a Python exception thrown by trying to load a missing file.
{"@version":1,"source_host":"<REDACTED>","message":"Unable to load native-hadoop library for your platform... using builtin-java classes where applicable","thread_name":"main","@timestamp":"2021-10-03T12:45:19.606+00:00","level":"WARN","logger_name":"org.apache.hadoop.util.NativeCodeLoader"}
{"@version":1,"source_host":"<REDACTED>","message":"Processing for date 2021/10/02","thread_name":"Thread-4","@timestamp":"2021-10-03T12:45:37.784+00:00","level":"INFO","logger_name":"root"}
{"@version":1,"source_host":"<REDACTED>","message":"Traceback (most recent call last):\n File \"<REDACTED>\", line 609, in <module>\n process(start_date.strftime(\"%Y/%m/%d\"))\n File \"<REDACTED>\", line 482, in process\n spark.read.format(\"json\").option(\"header\", \"true\").schema(schema).load(s3a)\n File \"/opt/spark/python/lib/pyspark.zip/pyspark/sql/readwriter.py\", line 204, in load\n return self._df(self._jreader.load(path))\n File \"/opt/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py\", line 1305, in __call__\n answer, self.gateway_client, self.target_id, self.name)\n File \"/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py\", line 117, in deco\n raise converted from None\npyspark.sql.utils.AnalysisException: Path does not exist: <REDACTED>\n","thread_name":"Thread-4","@timestamp":"2021-10-03T12:45:40.360+00:00","level":"ERROR","logger_name":"root"}
Figures 3.1, 3.2 and 3.3 demonstrate how these lines are displayed in the log manager of our choice, DataDog. This result is produced without any further configuration applied; the manager is able to deduce enough information from the raw JSON logs.
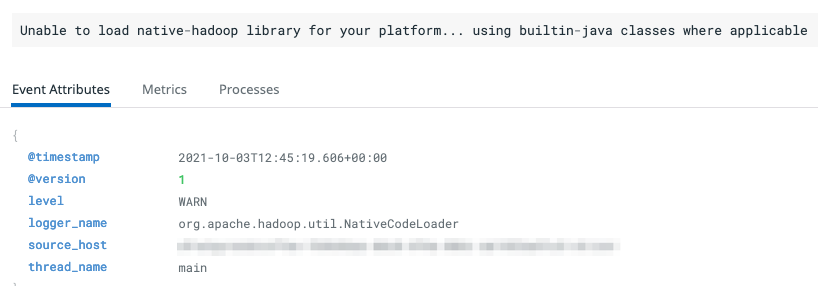
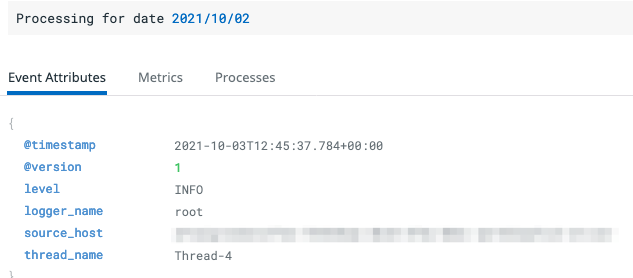
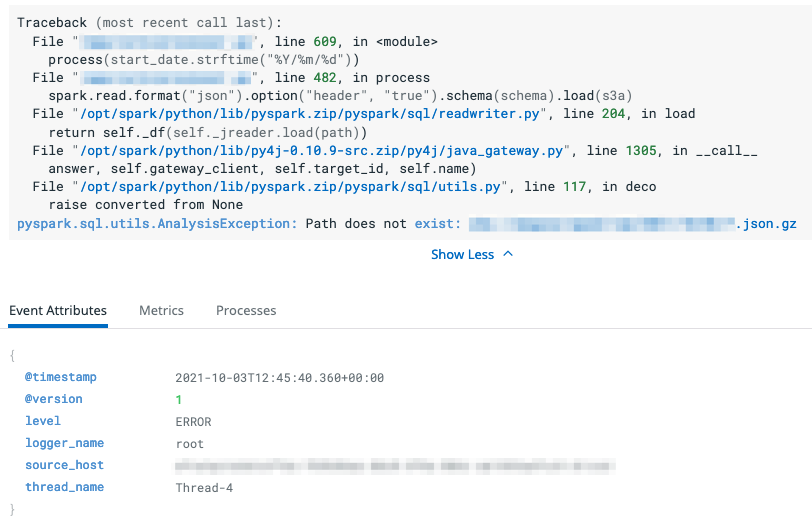
Improvements
Right now, it is somewhat annoying to change the log level of Spark, because it is defined statically in log4j2.properties. When the situation asks for a more verbose log level, we currently mount a different Properties file to override the default values. Externalising the log level through an environment variable would make this easier to achieve. As we don’t do this very frequently, the current implementation works fine for us.